|
I am a research scientist at Google Deepmind (Email: wendaxu@ucsb.edu, wendax@google.com). My research focuses on improving large language models (LLMs) through rigorous evaluation and efficient post-training. I actively develop automated methods to assess model capabilities, including efficient data curation technique for building challenge benchmarks. To complement this, I design unsupervised and explainable evaluation metrics. My work in this area led to SEScore1&2 and InstructScore, which was recognized as the best unsupervised metric at the WMT22 shared task. My background also includes developing efficient post-training techniques, from preference learning with BPO to knowledge distillation with Speculative KD. CV / Linkedin / Google Scholar / Twitter / Github |

|
NewsOn 11/18/2025, I joined Google Deemind as a research scientist, continue to work on Gemini evaluation and post-training.On 11/12/2025, Knowledge Distillation with Interleaved Sampling was filed a patent with legacy IDF number IDF-320078. On 4/15/2025, I joined Google as a research scientist, working on Gemini evaluation and post-training. On 3/7/2025, I successfuly defended my PhD and submit my thesis (On Evaluation and Efficient Post-training for LLMs). Speculative knowledge distillation was accepted by ICLR2025! |
Industry ExperienceGoogle DeepmindPosition: Research ScientistDuration: 11/2025 - Now - Gemini Evaluation and Post-training Google Translate ResearchPosition: Research ScientistDuration: 04/2025 - 11/2025 Publication: Publication: Publication: Publication: - Developed and scaled an automated pipeline to generate dynamic challenge sets for evaluating Gemini models across both pre-training and post-training stages. - Led the research efforts in automatic benchmark construction using LLMs, studying both self-bias in LLM-generated benchmark and efficient auto-challenge set construction. - Led the research efforts in studying length bias of translation evaluation metric. Google Cloud AI ResearchDuration: 06/2024 - 10/2024Mentors: Chen-Yu Lee, Rishabh Agarwal Hosts: Rujun Han, Zifeng Wang Publication: - Built a generic KD framework that generalizes to on-policy and supervised KD, achieves substantial gains in task specific and task agnostic knowledge distillation (now deployed in production at Google Translate). Google Translate ResearchDuration: 06/2023 - 12/2023Mentors: Markus Freitag Hosts: Dan Deutsch, Mara Finkelstein, Juraj Juraska Publication: - Developed an efficient, inference-time optimization technique that iteratively refines PaLM 2 outputs at the span level, which has been successfully deployed in production by the YouTube team. ByteDance AI LabDuration: 06/2022 - 10/2022Mentors: Mingxuan Wang Hosts: Xian Qian Publication: - Developed a learned evaluation metric without human labels that achieved high correlation with human judgment and greatly improves the assessment of translation quality. |
Efficient Post-training |
|
|
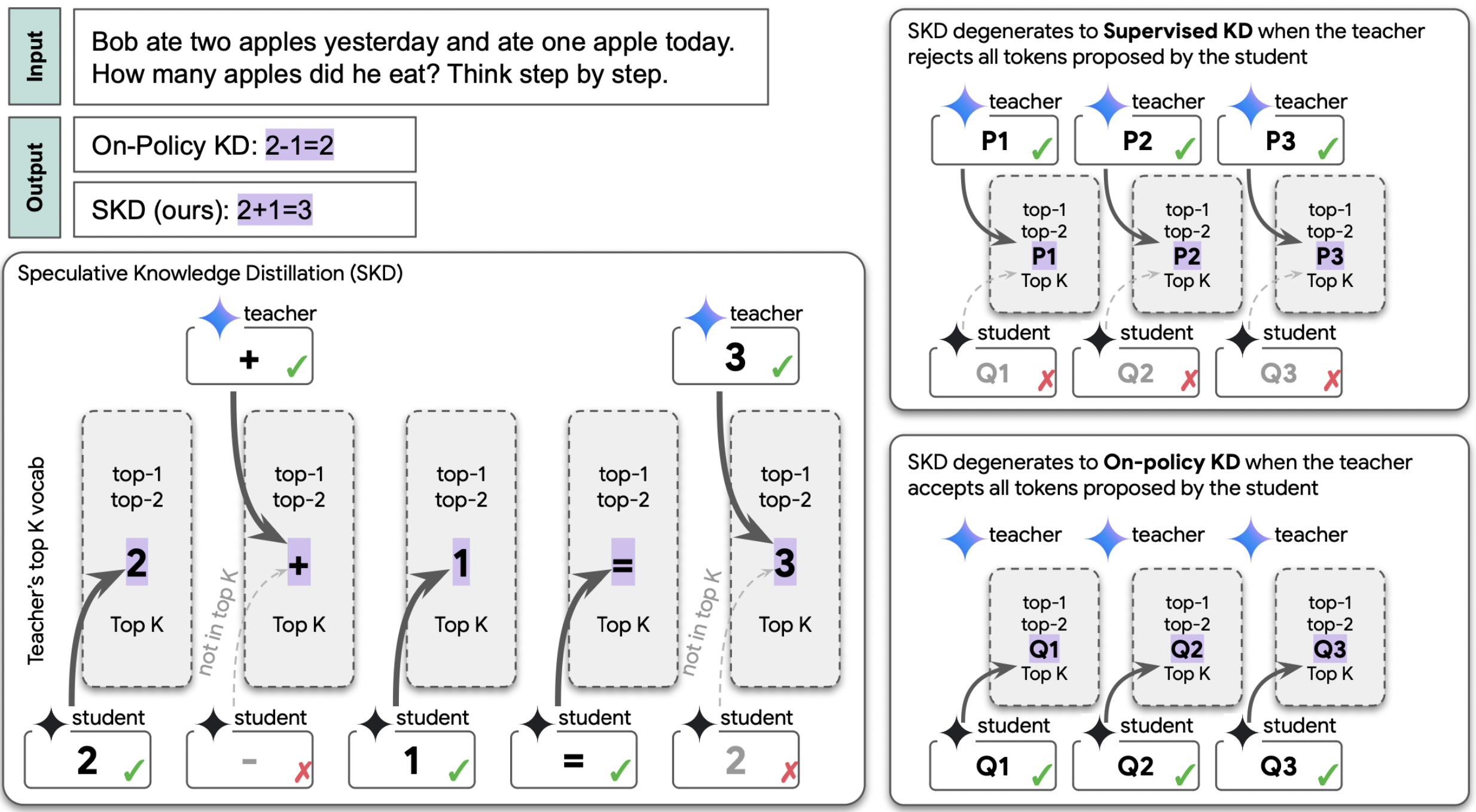
|
Wenda Xu, Rujun Han, Zifeng Wang, Long Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, Tomas Pfister ICLR 2025 project page / arXiv / code A generic KD framework that generalizes to on-policy and supervised KD, achieves substantial gains in task specific and task agnostic knowledge distillation. |
|
|
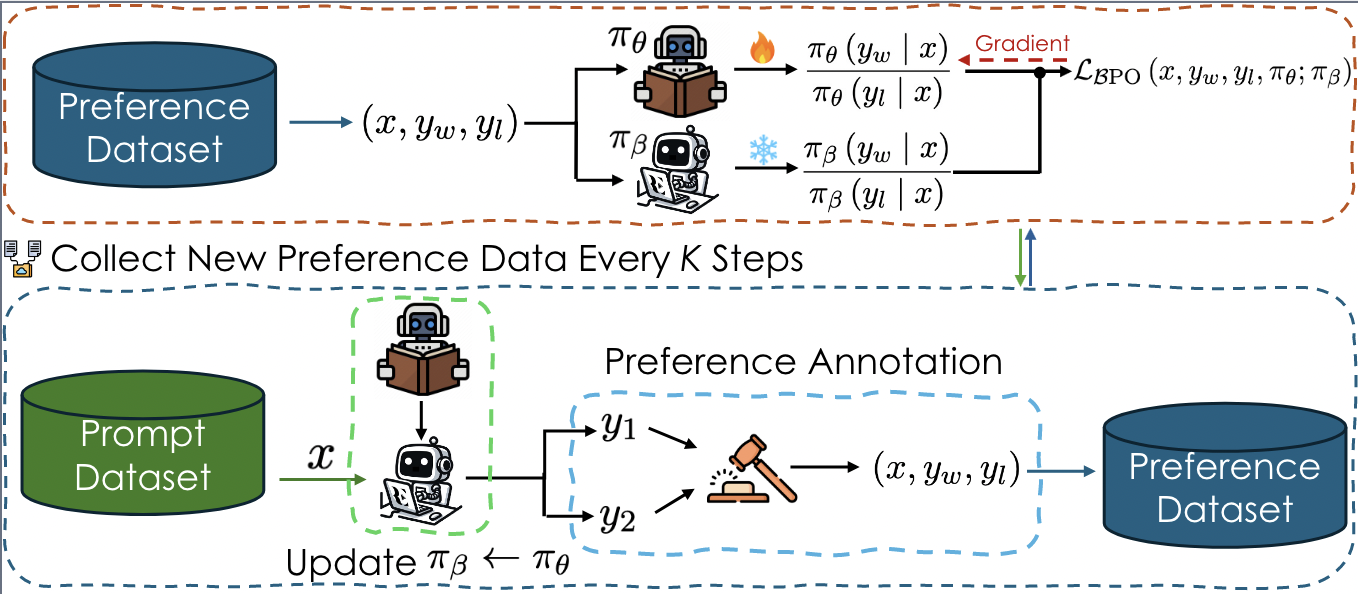
|
Wenda Xu*, Jiachen Li*, William Yang Wang, Lei Li *Two authors contributed equally EMNLP Main 2024 project page / arXiv / code On-policy BPO achieves superior performance compared to DPO on TL;DR (89.5% vs 72.0%), Helpfulness (93.5% vs 82.2%), and Harmfulness (97.7% vs 77.5%). |
|
|

|
Wenda Xu, Michael Saxon, Misha Sra, William Yang Wang AAAI2022 project page / arXiv / code We develop a novel self-supervised approach to perform expert layman text style transfer, relative improvement in overall success rate at text style transfer by 106%. |
|
|

|
Wenda Xu, Daniel Deutsch, Mara Finkelstein, Juraj Juraska, Biao Zhang, Zhongtao Liu, William Yang Wang, Lei Li, Markus Freitag NAACL 2024 project page / arXiv / code An efficient inference time optimization technique that iteratively refines the outputs of the PaLM 2 model at text span-level, achieving improvements of 1.7 MetricX on translation, 8.1 ROUGE-L on ASQA, and 2.2 ROUGE-L on topical summarization. |
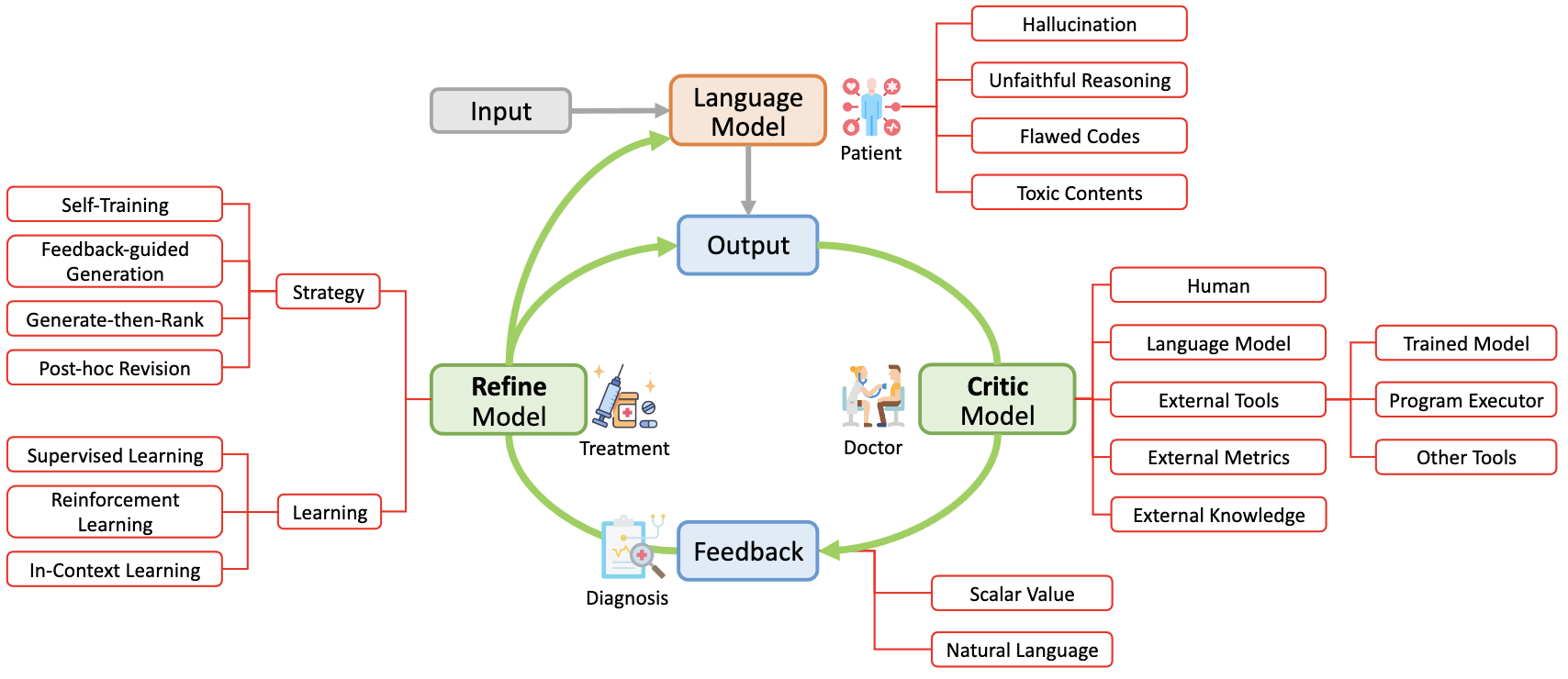
|
Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, William Yang Wang TACL 2024 arXiv / code A survey of self-correct strategies of LLM, including training-time, generation-time and inference-time approaches. |
Large Language Model Evaluation |
|
|
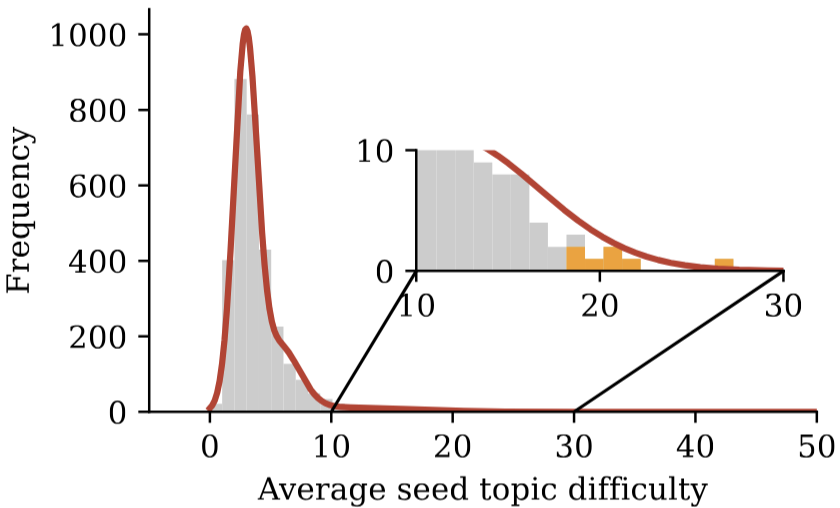
|
Wenda Xu*, Vilém Zouhar*, Parker Riley, Mara Finkelstein, Markus Freitag, Daniel Deutsch *Two authors contributed equally Preprint project page / arXiv / code A scalable and efficient automatic data curation technique for building model-specific challenge benchmarks by finding the most difficult test examples. |
|
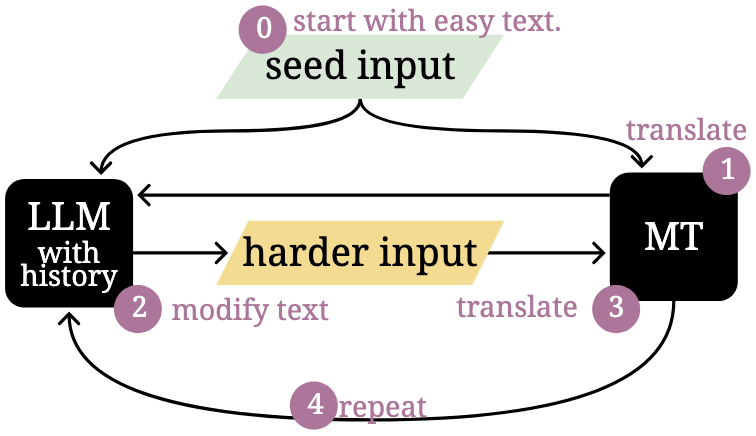
Vilém Zouhar, Wenda Xu*, Parker Riley, Juraj Juraska, Mara Finkelstein, Markus Freitag, Daniel Deutsch Preprint project page / arXiv / code MT-breaker, employs a LLM to iteratively generate difficult yet natural prompt examples to build more challenging translation benchmarks. |
|
|
|
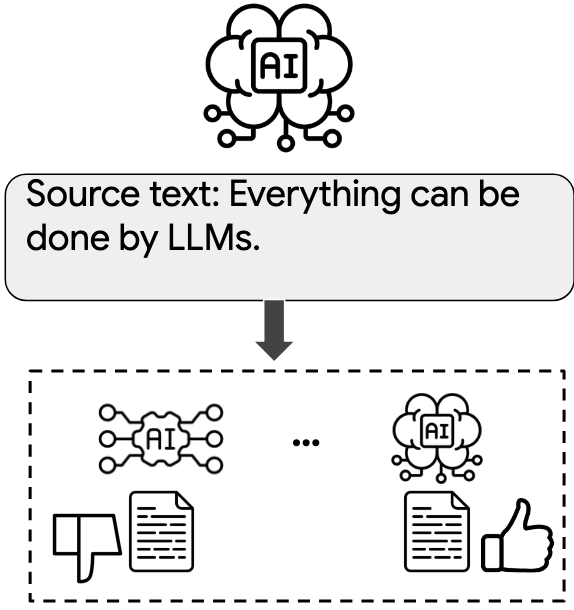
Wenda Xu, Sweta Agrawal, Vilém Zouhar, Markus Freitag, Daniel Deutsch Preprint project page / arXiv / code We demonstrate that LLM-generated benchmarks exhibit a systematic self-bias that inflates a model's own performance, and low source text diversity is one primary cause. |
|
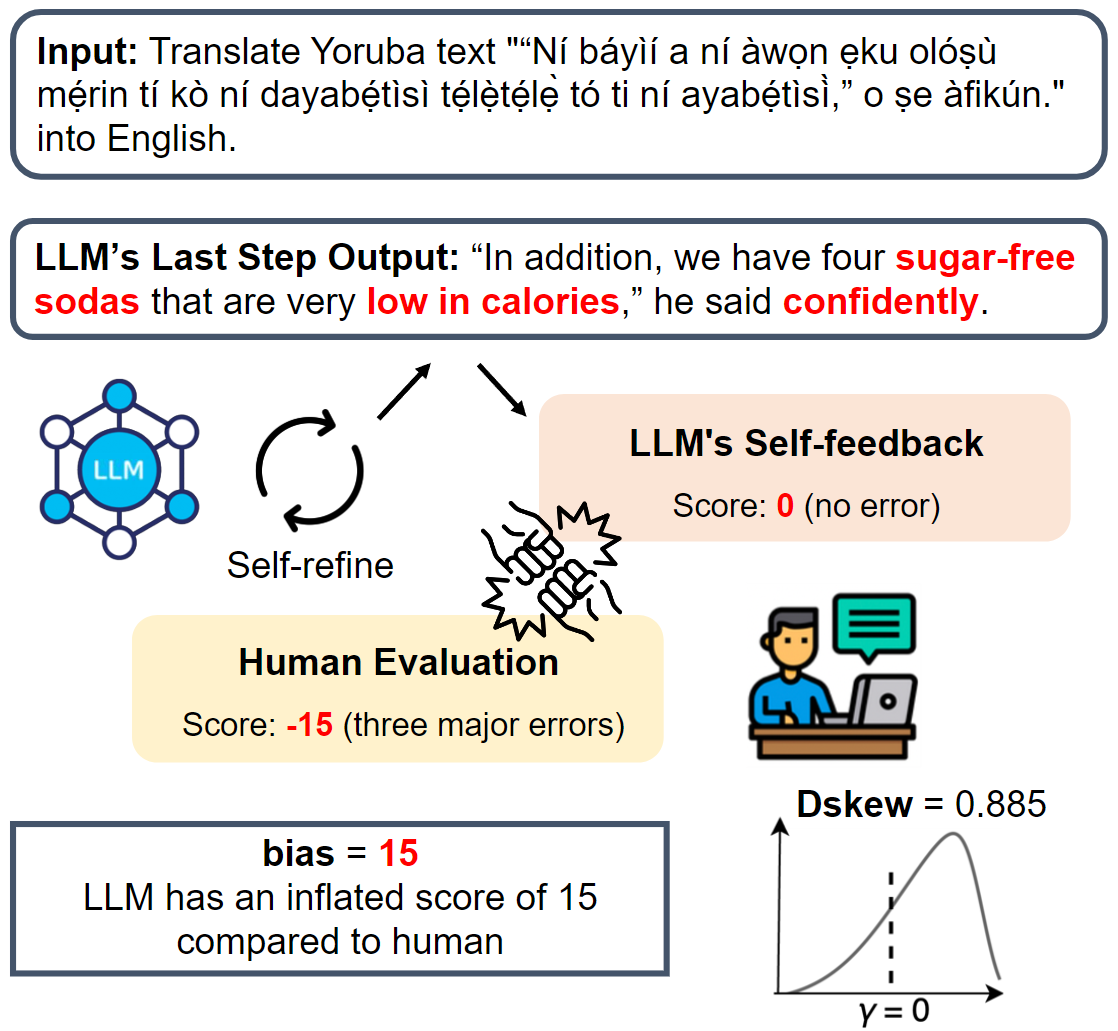
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, William Yang Wang ACL 2024 Main (Oral) project page / arXiv / code The study to define and quantify the bias exhibited by LLMs when assessing their own generated outputs. |
|
|
|
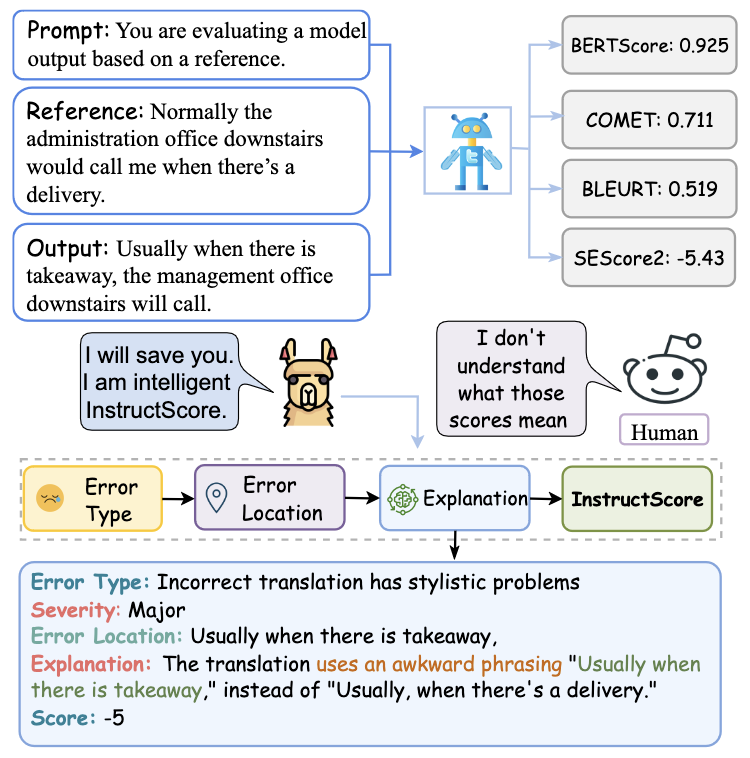
Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Yang Wang, Lei Li EMNLP Main 2023 (Oral) project page / arXiv / code A fine-grained 7B LLM autorater (detect errors at span level), trained on synthetic data, surpasses unsupervised metrics, including those based on 175B GPT-3 and GPT-4. |
|
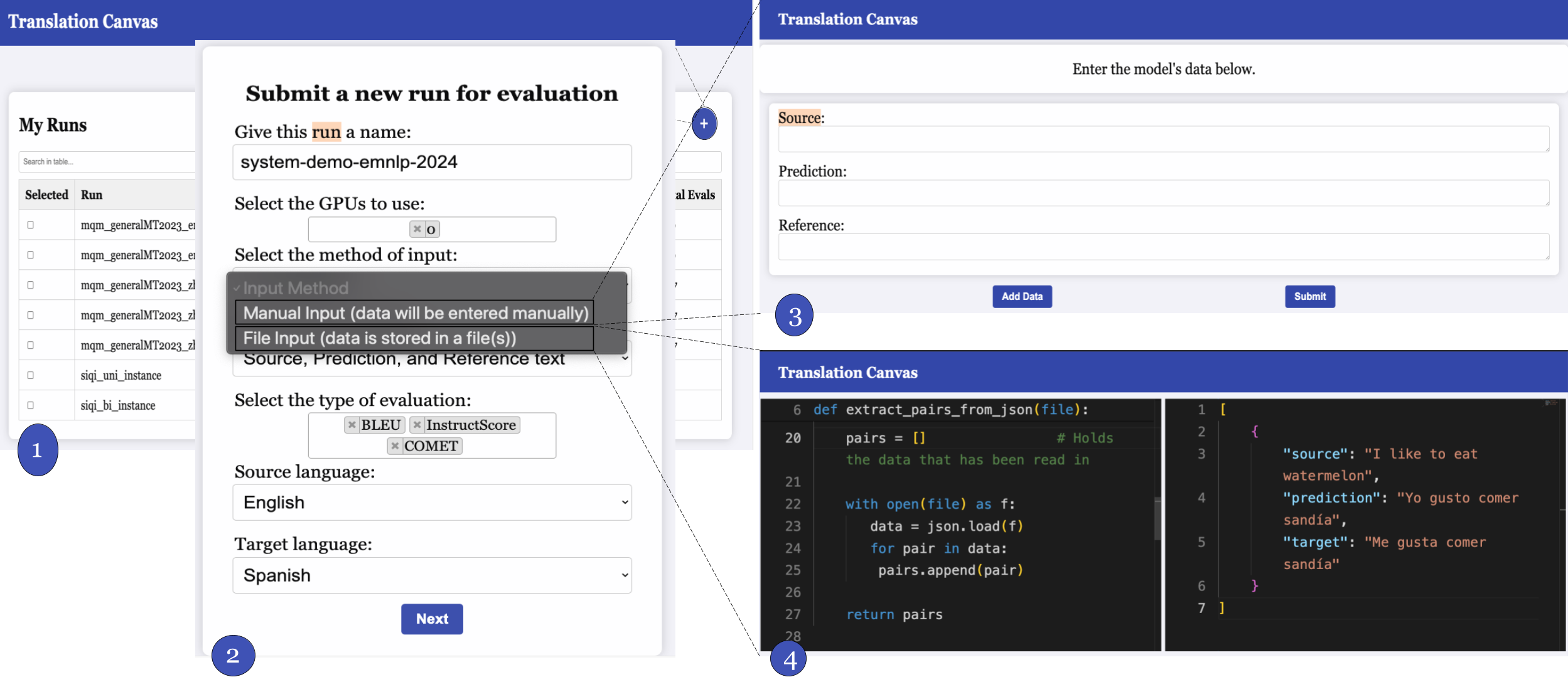
Chinmay Dandekar, Wenda Xu, Xi Xu, Siqi Ouyang, Lei Li EMNLP 2024 Demo arXiv / code System demonstration of InstructScore. |
|
|
|
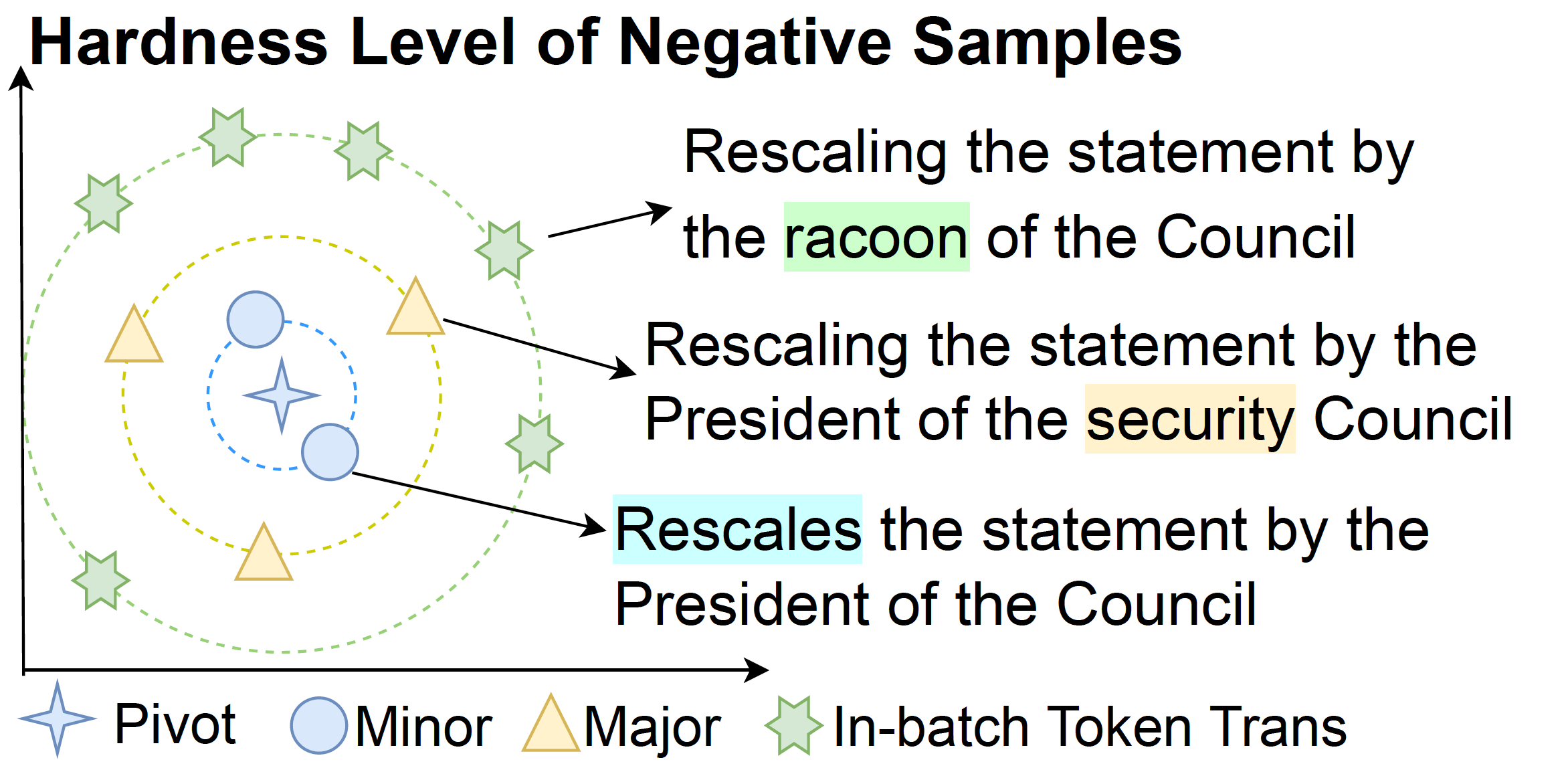
Wenda Xu, Xian Qian, Mingxuan Wang, Lei Li, William Yang Wang ACL Main 2023 project page / arXiv / code SESCORE2, is a SSL method to train a metric for general text generation tasks without human ratings, kendall correlation improved 14.3% from SEScore. |

|
Wenda Xu, Yi-lin Tuan, Yujie Lu, Michael Saxon, Lei Li, William Yang Wang EMNLP2022 and also appeared at WMT22 shared metric task (Best unsupervised metric) project page / arXiv / code / HuggingFace SEScore is a reference-based text-generation evaluation metric that requires no pre-human-annotated data to train on. We develop a novel stratified error synthesis to synthesize diverse errors with varying severity levels at raw data. |
Collaboration Publications |
|
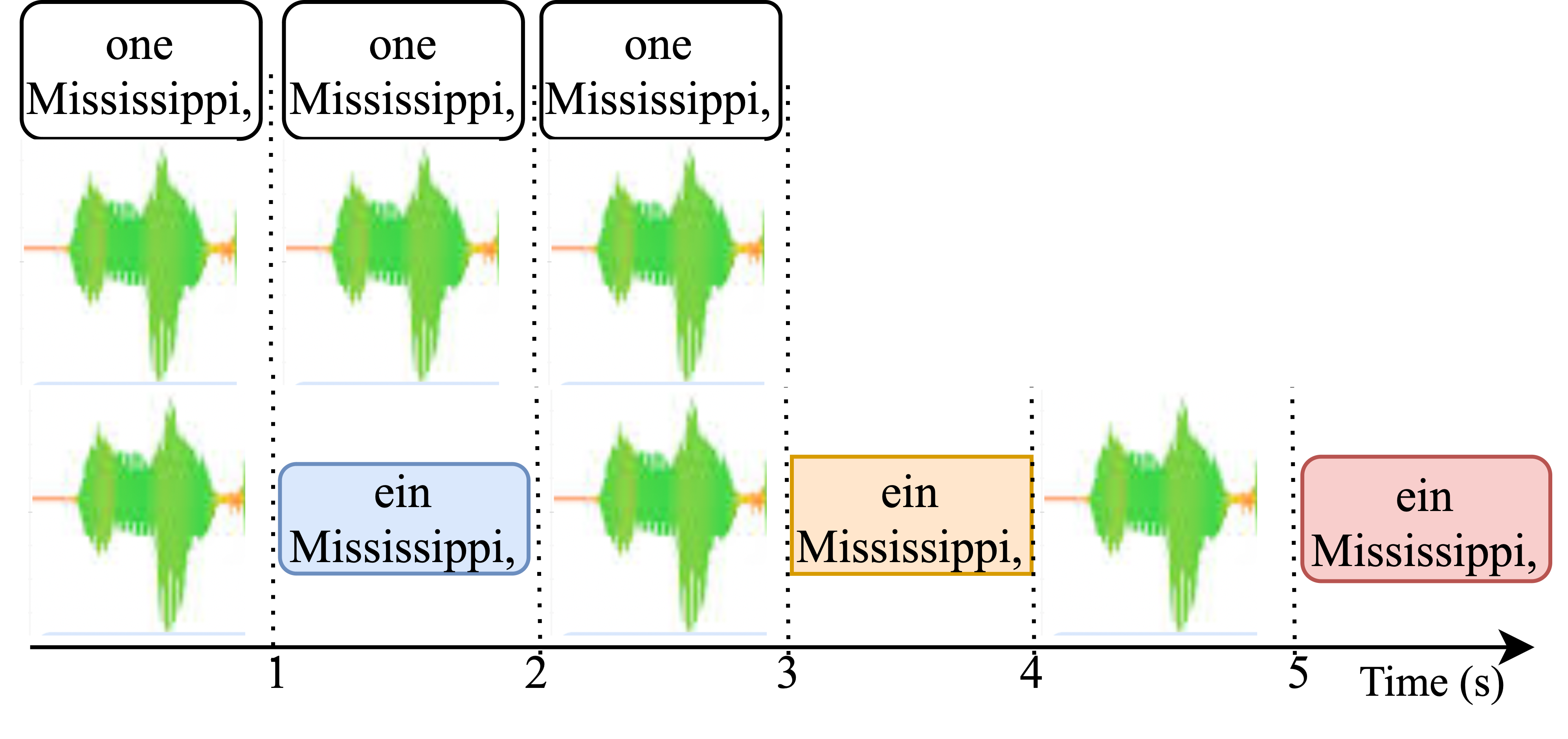
Xi Xu, Wenda Xu, Siqi Ouyang, Lei Li NAACL 2025 arXiv / code We reveal the root problems of exisitng latency evaluations at speech translation. |
|
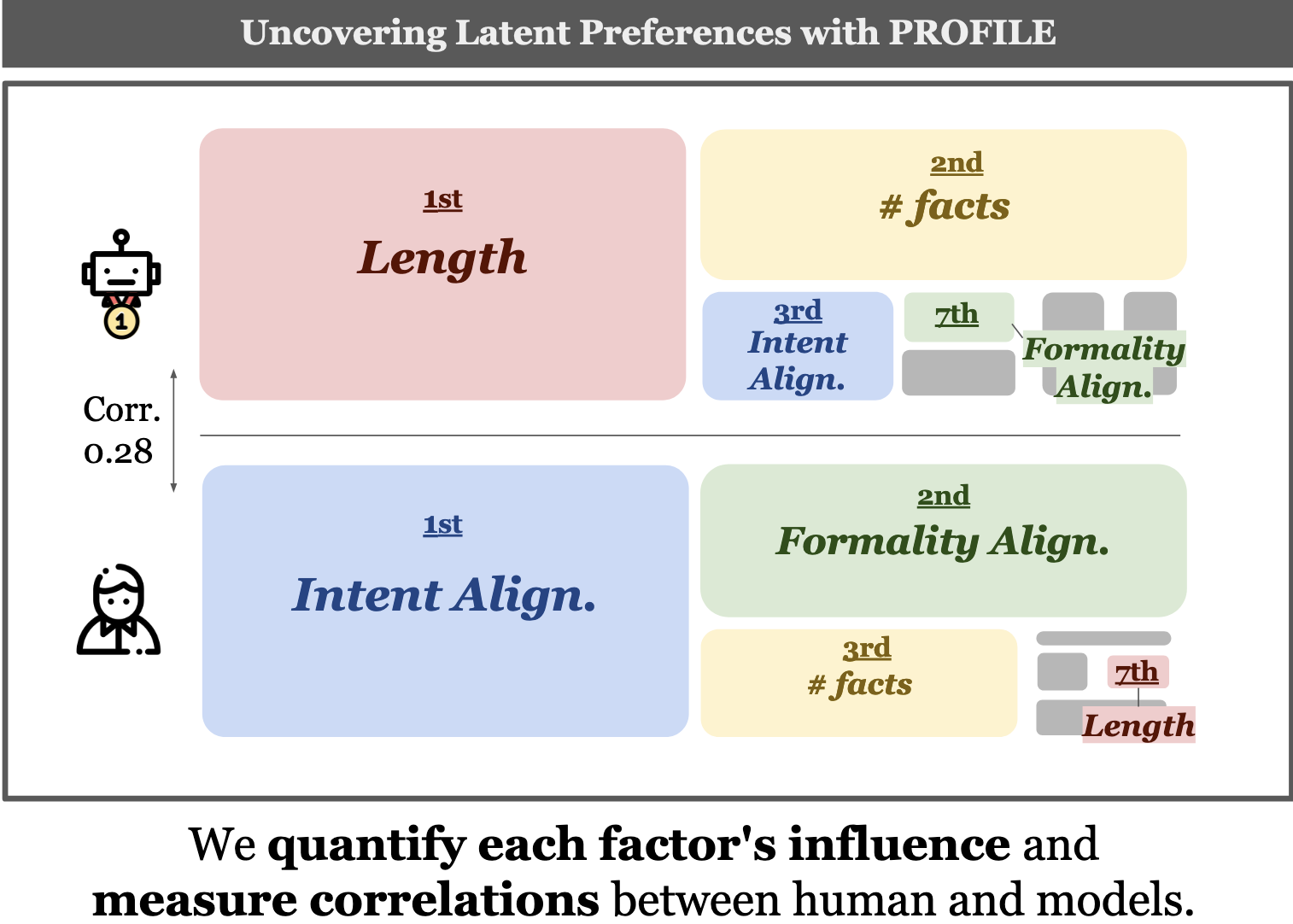
Juhyun Oh, Eunsu Kim, Jiseon Kim, Wenda Xu, Inha Cha, William Yang Wang, Alice Oh Preprint arXiv / code A novel framework that uncovers and quantifies the influence of specific factors driving preferences, exposing the gap of model's understanding and generation capability. |
|
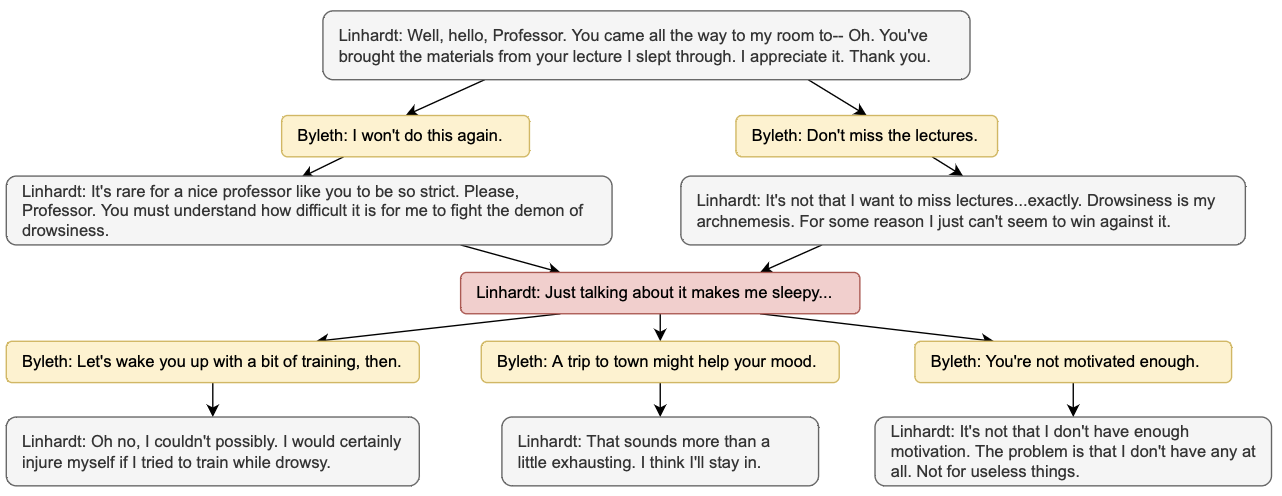
Yi-Lin Tuan, Alon Albalak, Wenda Xu, Michael Saxon, Connor Pryor, Lise Getoor, William Yang Wang ACL 2023 arXiv / code New work explores the causal relationship encoded in branching dialogue graphs from RPG video game. |

|
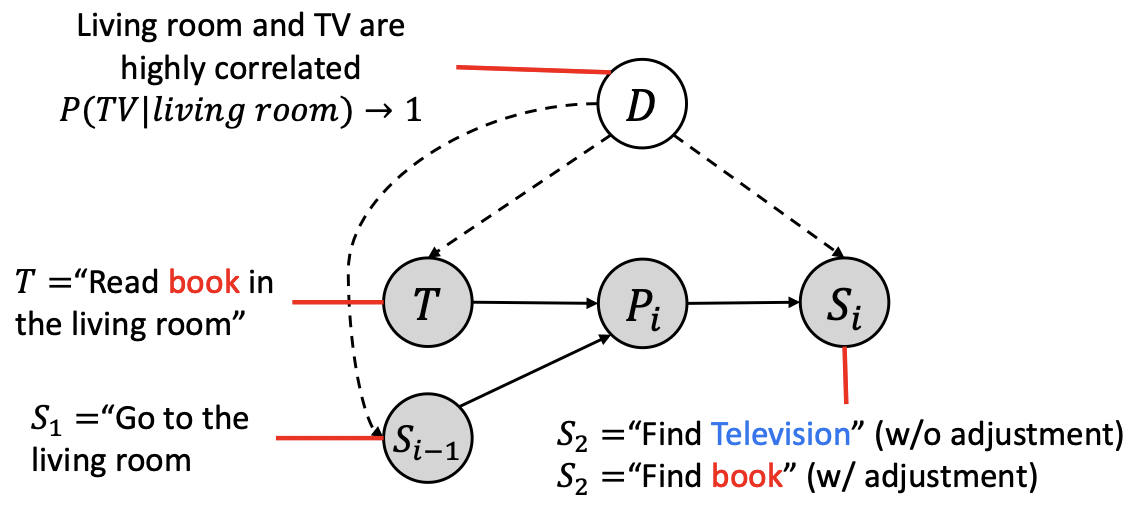
Michael Saxon, Xinyi Wang, Wenda Xu, William Yang Wang EACL 2023 arXiv / code We demonstrated automated detection of spurious, annotator-driven correlations that lead to cheating features in NLI. |
|
Yujie Lu, Weixi Feng, Wanrong Zhu, Wenda Xu, Xin Eric Wang, Miguel Eckstein, William Yang Wang ICLR 2023 arXiv / code This work mitigates spurious correlations by using symbolic program executors on latent procedural representations
|
|
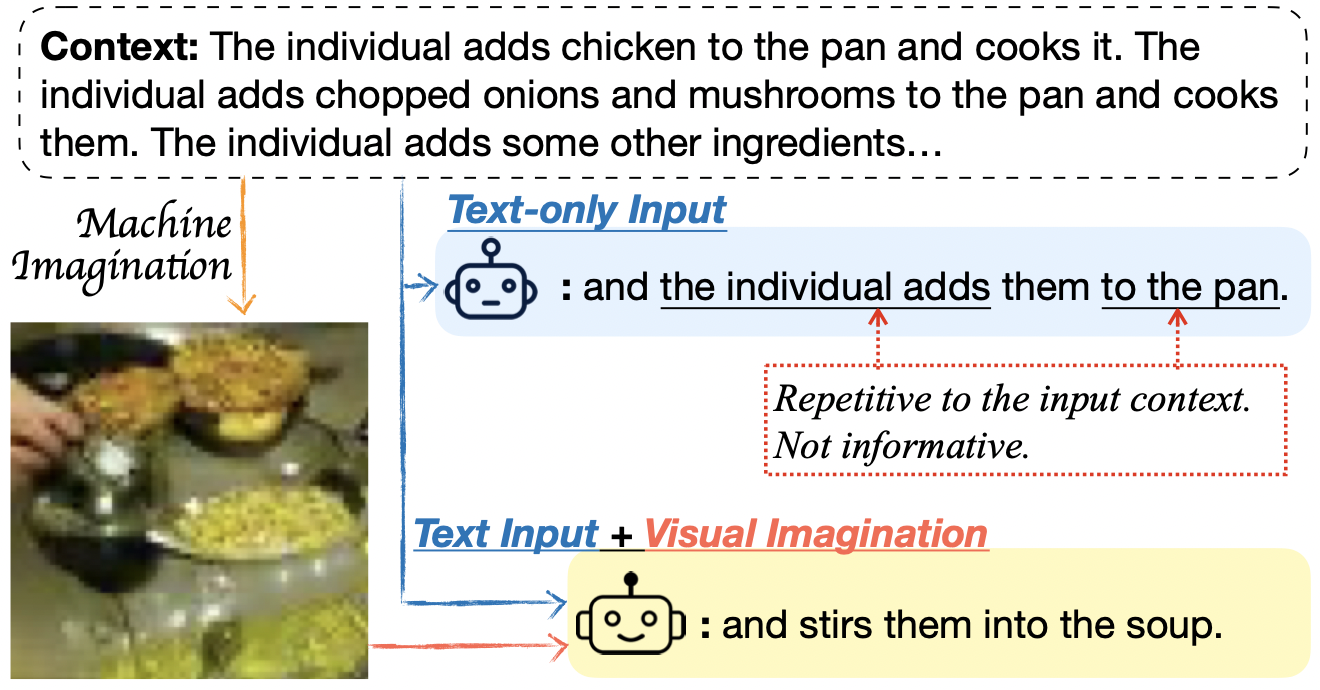
Wanrong Zhu, An Yan, Yujie Lu, Wenda Xu, Xin Eric Wang, Miguel Eckstein, William Yang Wang EACL 2023 arXiv / code Introduce a novel paradigm that leverages machine-generated images to guide open-ended text generation. This endows the machines with the ability of creative visualization that human writers often demonstrate.
|

|
Fun Fact: What is the meaning of Wenda(闻达)?I add this because Starbucks people keep putting down "Wendy" or "Wanda"子张问:“士何如斯可谓之达矣?”子曰:“何哉,尔所谓达者?” 子张对曰:“在邦必闻,在家必闻。” 子曰:“是闻也,非达也。夫达也者,质直而好义,察言而观色,虑以下人。在邦必达,在家必达。夫闻也者,色取仁而行违,居之不疑。在邦必闻,在家必闻。” The origin of word "Wenda(闻达)" was from a conversation between Confucius and his student. Here is the English translation: Zi Zhang asked, "What makes a scholar truly accomplished ('Da' means 'accomplished', 达)?" Confucius asked, "Define 'accomplished'?" Zi Zhang replied, "To be renowned in the states of feudal lords, and to be renowned in the lands of ministers." Confucius said, "This is more about fame ('Wen' means 'fame', 闻) than accomplishment. True accomplishment is about honesty, love for righteousness, understanding others, and modesty. Such a person will succeed anywhere. Those who seek fame may pretend to be virtuous, but their actions betray them, leading to hollow fame regardless of where they are."
|